Research

|
RoboCade: Gamifying Robot Data Collection Suvir Mirchandani*, Mia Tang*, Jiafei Duan, Jubayer Ibn Hamid, Michael Cho, Dorsa Sadigh International Conference on Robotics and Automation (ICRA), June 2026
BibTeX
Abstract
arXiv
Website
@inproceedings{mirchandanitang2026robocade, title={RoboCade: Gamifying Robot Data Collection}, author={Mirchandani, Suvir and Tang, Mia and Duan, Jiafei and Hamid, Jubayer Ibn and Cho, Michael and Sadigh, Dorsa}, booktitle={International Conference on Robotics and Automation}, year={2026}, month=june } Imitation learning from human demonstrations has become a dominant approach for training autonomous robot policies. However, collecting demonstration datasets is costly: it often requires access to robots and needs sustained effort in a tedious, long process. These factors limit the scale of data available for training policies. We aim to address this scalability challenge by involving a broader audience in a gamified data collection experience that is both accessible and motivating. Specifically, we develop a gamified remote teleoperation platform, RoboCade, to engage general users in collecting data that is beneficial for downstream policy training. To do this, we embed gamification strategies into the design of the system interface and data collection tasks. In the system interface, we include components such as visual feedback, sound effects, goal visualizations, progress bars, leaderboards, and badges. We additionally propose principles for constructing gamified tasks that have overlapping structure with useful downstream target tasks. We instantiate RoboCade on three manipulation tasks—including spatial arrangement, scanning, and insertion. To illustrate the viability of gamified robot data collection, we collect a demonstration dataset through our platform, and show that co-training robot policies with this data can improve success rate on non-gamified target tasks (+16-56%). Further, we conduct a user study to validate that novice users find the gamified platform significantly more enjoyable than a standard non-gamified platform (+24%). These results highlight the promise of gamified data collection as a scalable, accessible, and engaging method for collecting demonstration data. |

|
Training Strategies for Efficient Embodied Reasoning William Chen, Suneel Belkhale, Suvir Mirchandani, Oier Mees, Danny Driess, Karl Pertsch, Sergey Levine Conference on Robot Learning (CoRL), September 2025 Oral Presentation
BibTeX
Abstract
arXiv
Website
@inproceedings{chen2025training, title={Training Strategies for Efficient Embodied Reasoning}, author={Chen, William and Belkhale, Suneel and Mirchandani, Suvir and Mees, Oier and Driess, Danny and Pertsch, Karl and Levine, Sergey}, booktitle={Conference on Robot Learning (CoRL)}, year={2025}, } Robot chain-of-thought reasoning (CoT) -- wherein a model predicts helpful intermediate representations before choosing actions -- provides an effective method for improving the generalization and performance of robot policies, especially vision-language-action models (VLAs). While such approaches have been shown to improve performance and generalization, they suffer from core limitations, like needing specialized robot reasoning data and slow inference speeds. To design new robot reasoning approaches that address these issues, a more complete characterization of why reasoning helps policy performance is critical. We hypothesize several mechanisms by which robot reasoning improves policies -- (1) better representation learning, (2) improved learning curricularization, and (3) increased expressivity -- then devise simple variants of robot CoT reasoning to isolate and test each one. We find that learning to generate reasonings does lead to better VLA representations, while attending to the reasonings aids in actually leveraging these features for improved action prediction. Our results provide us with a better understanding of why CoT reasoning helps VLAs, which we use to introduce two simple and lightweight alternative recipes for robot reasoning. Our proposed approaches achieve significant performance gains over non-reasoning policies, state-of-the-art results on the LIBERO-90 benchmark, and a 3x inference speedup compared to standard robot reasoning. |

|
Action-Free Reasoning for Policy Generalization Jaden Clark, Suvir Mirchandani, Dorsa Sadigh, Suneel Belkhale Conference on Robot Learning (CoRL), September 2025
BibTeX
Abstract
arXiv
Website
@inproceedings{clark2025action, title={Action-Free Reasoning for Policy Generalization}, author={Clark, Jaden and Mirchandani, Suvir and Sadigh, Dorsa and Belkhale, Suneel}, booktitle={Conference on Robot Learning (CoRL)}, year={2025}, month=sep } End-to-end imitation learning offers a promising approach for training robot policies. However, generalizing to new settings—such as unseen scenes, tasks, and object instances—remains a significant challenge. Although large-scale robot demonstration datasets have shown potential for inducing generalization, they are resource-intensive to scale. In contrast, human video data is abundant and diverse, presenting an attractive alternative. Yet, these human-video datasets lack action labels, complicating their use in imitation learning. Existing methods attempt to extract grounded action representations (e.g., hand poses), but resulting policies struggle to bridge the embodiment gap between human and robot actions. We propose an alternative approach: leveraging language-based reasoning from human videos - essential for guiding robot actions - to train generalizable robot policies. Building on recent advances in reasoning-based policy architectures, we introduce Reasoning through Action-free Data (RAD). RAD learns from both robot demonstration data (with reasoning and action labels) and action-free human video data (with only reasoning labels). The robot data teaches the model to map reasoning to low-level actions, while the action-free data enhances reasoning capabilities. Additionally, we will release a new dataset of 3,377 human-hand demonstrations compatible with the Bridge V2 benchmark. This dataset includes chain-of-thought reasoning annotations and hand-tracking data to help facilitate future work on reasoning-driven robot learning. Our experiments demonstrate that RAD enables effective transfer across the embodiment gap, allowing robots to perform tasks seen only in action-free data. Furthermore, scaling up action-free reasoning data significantly improves policy performance and generalization to novel tasks. These results highlight the promise of reasoning-driven learning from action-free datasets for advancing generalizable robot control. |
|
Robot Data Curation with Mutual Information Estimators Joey Hejna, Suvir Mirchandani, Ashwin Balakrishna, Annie Xie, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, Dhruv Shah, Coline Devin, Dorsa Sadigh Robotics: Science and Systems (RSS), June 2025
BibTeX
Abstract
arXiv
Website
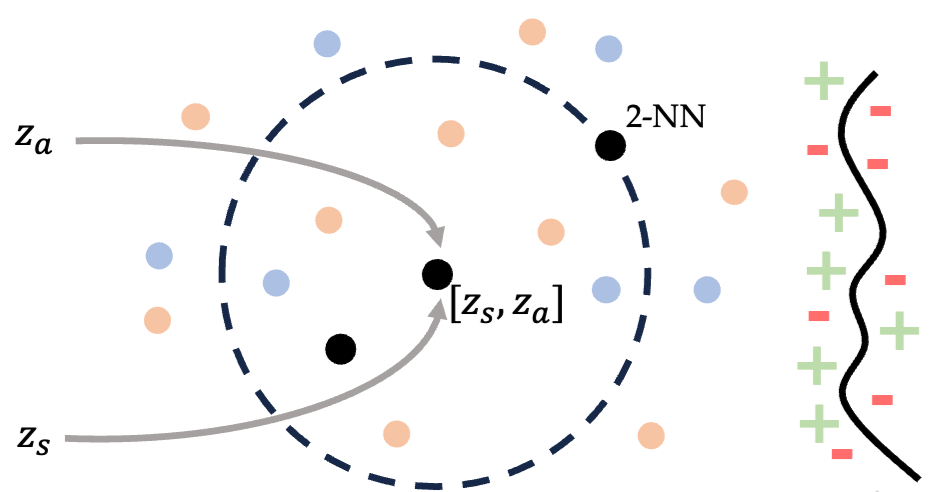
@inproceedings{hejna2025robot, title={Robot Data Curation with Mutual Information Estimators}, authors={Hejna, Joey and Mirchandani, Suvir and Balakrishna, Ashwin and Xie, Annie and Wahid, Ayzaan and Tompson, Jonathan and Sanketi, Pannag and Shah, Dhruv and Devin, Coline and Sadigh, Dorsa}, booktitle={Robotics: Science and Systems (RSS)}, year={2025}, month=june } The performance of imitation learning policies often hinges on the datasets with which they are trained. Consequently, investment in data collection for robotics has grown across both industrial and academic labs. However, despite the marked increase in the quantity of demonstrations collected, little work has sought to assess the quality of said data despite mounting evidence of its importance in other areas such as vision and language. In this work, we take a critical step towards addressing the data quality in robotics. Given a dataset of demonstrations, we aim to estimate the relative quality of individual demonstrations in terms of both action diversity and predictability. To do so, we estimate the average contribution of a trajectory towards the mutual information between states and actions in the entire dataset, which captures both the entropy of the marginal action distribution and the state-conditioned action entropy. Though commonly used mutual information estimators require vast amounts of data often beyond the scale available in robotics, we introduce a novel technique based on k-nearest neighbor estimates of mutual information on top of simple VAE embeddings of states and actions. Empirically, we demonstrate that our approach is able to partition demonstration datasets by quality according to human expert scores across a diverse set of benchmarks spanning simulation and real world environments. Moreover, training policies based on data filtered by our method leads to a 5-10% improvement in RoboMimic and better performance on real ALOHA and Franka setups. |
|
What Matters for Batch Online Reinforcement Learning in Robotics? Perry Dong, Suvir Mirchandani, Dorsa Sadigh, Chelsea Finn International Conference on Learning Representations (ICLR), April 2026
BibTeX
Abstract
arXiv
Website
@inproceedings{dong2026batch, title={What Matters for Batch Online Reinforcement Learning in Robotics?}, author={Dong, Perry and Mirchandani, Suvir and Sadigh, Dorsa and Finn, Chelsea}, booktitle={International Conference on Learning Representations (ICLR)}, year={2026}, month=apr } The ability to learn from large batches of autonomously collected data for policy improvement -- a paradigm we refer to as batch online reinforcement learning -- holds the promise of enabling truly scalable robot learning by significantly reducing the need for human effort of data collection while getting benefits from self-improvement. Yet, despite the promise of this paradigm, it remains challenging to achieve due to algorithms not being able to learn effectively from the autonomous data. For example, prior works have applied imitation learning and filtered imitation learning methods to the batch online RL problem, but these algorithms often fail to efficiently improve from the autonomously collected data or converge quickly to a suboptimal point. This raises the question of what matters for effective batch online RL in robotics. Motivated by this question, we perform a systematic empirical study of three axes -- (i) algorithm class, (ii) policy extraction methods, and (iii) policy expressivity -- and analyze how these axes affect performance and scaling with the amount of autonomous data. Through our analysis, we make several observations. First, we observe that the use of Q-functions to guide batch online RL significantly improves performance over imitation-based methods. Building on this, we show that an implicit method of policy extraction -- via choosing the best action in the distribution of the policy -- is necessary over traditional policy extraction methods from offline RL. Next, we show that an expressive policy class is preferred over less expressive policy classes. Based on this analysis, we propose a general recipe for effective batch online RL. We then show a simple addition to the recipe of using temporally-correlated noise to obtain more diversity results in further performance gains. Our recipe obtains significantly better performance and scaling compared to prior methods. |

|
RoboCrowd: Scaling Robot Data Collection through Crowdsourcing Suvir Mirchandani, David D. Yuan, Kaylee Burns, Md Sazzad Islam, Tony Z. Zhao, Chelsea Finn, Dorsa Sadigh International Conference on Robotics and Automation (ICRA), May 2025 Best Conference Paper Award Finalist
BibTeX
Abstract
arXiv
Website
@inproceedings{mirchandani2025robocrowd, title={RoboCrowd: Scaling Robot Data Collection through Crowdsourcing}, author={Mirchandani, Suvir and Yuan, David D. and Burns, Kaylee and Islam, Md Sazzad and Zhao, Tony Z. and Finn, Chelsea and Sadigh, Dorsa}, booktitle={International Conference on Robotics and Automation (ICRA)}, year={2025}, month=may } In recent years, imitation learning from large-scale human demonstrations has emerged as a promising paradigm for training robot policies. However, the burden of collecting large quantities of human demonstrations is significant in terms of collection time and the need for access to expert operators. We introduce a new data collection paradigm, RoboCrowd, which distributes the workload by utilizing crowdsourcing principles and incentive design. RoboCrowd helps enable scalable data collection and facilitates more efficient learning of robot policies. We build RoboCrowd on top of ALOHA (Zhao et al. 2023) -- a bimanual platform that supports data collection via puppeteering -- to explore the design space for crowdsourcing in-person demonstrations in a public environment. We propose three classes of incentive mechanisms to appeal to users' varying sources of motivation for interacting with the system: material rewards, intrinsic interest, and social comparison. We instantiate these incentives through tasks that include physical rewards, engaging or challenging manipulations, as well as gamification elements such as a leaderboard. We conduct a large-scale, two-week field experiment in which the platform is situated in a university cafe. We observe significant engagement with the system -- over 200 individuals independently volunteered to provide a total of over 800 interaction episodes. Our findings validate the proposed incentives as mechanisms for shaping users' data quantity and quality. Further, we demonstrate that the crowdsourced data can serve as useful pre-training data for policies fine-tuned on expert demonstrations -- boosting performance up to 20% compared to when this data is not available. These results suggest the potential for RoboCrowd to reduce the burden of robot data collection by carefully implementing crowdsourcing and incentive design principles. |

|
Vocal Sandbox: Continual Learning and Adaptation for Situated Human-Robot Collaboration Jennifer Grannen*, Siddharth Karamcheti*, Suvir Mirchandani, Percy Liang, Dorsa Sadigh Conference on Robot Learning (CoRL), November 2024 Oral Presentation
BibTeX
Abstract
arXiv
Website
@inproceedings{grannen2024vocal, title={Vocal Sandbox: Continual Learning and Adaptation for Situated Human-Robot Collaboration}, author={Grannen, Jennifer and Karamcheti, Siddharth and Mirchandani, Suvir and Liang, Percy and Sadigh, Dorsa}, booktitle={Conference on Robot Learning (CoRL)}, year={2024}, month=nov } We introduce Vocal Sandbox, a framework for enabling seamless human-robot collaboration in situated environments. Systems in our framework are characterized by their ability to adapt and continually learn at multiple levels of abstraction from diverse teaching modalities such as spoken dialogue, object keypoints, and kinesthetic demonstrations. To enable such adaptation, we design lightweight and interpretable learning algorithms that allow users to build an understanding and co-adapt to a robot's capabilities in real-time, as they teach new behaviors. For example, after demonstrating a new low-level skill for 'tracking around' an object, users are provided with trajectory visualizations of the robot's intended motion when asked to track a new object. Similarly, users teach high-level planning behaviors through spoken dialogue, using pretrained language models to synthesize behaviors such as 'packing an object away' as compositions of low-level skills − concepts that can be reused and built upon. We evaluate Vocal Sandbox in two settings: collaborative gift bag assembly and LEGO stop-motion animation. In the first setting, we run systematic ablations and user studies with 8 non-expert participants, highlighting the impact of multi-level teaching. Across 23 hours of total robot interaction time, users teach 17 new high-level behaviors with an average of 16 novel low-level skills, requiring 22.1% less active supervision compared to baselines and yielding more complex autonomous performance (+19.7%) with fewer failures (-67.1%). Qualitatively, users strongly prefer Vocal Sandbox systems due to their ease of use (+20.6%) and overall performance (+13.9%). Finally, we pair an experienced system-user with a robot to film a stop-motion animation; over two hours of continuous collaboration, the user teaches progressively more complex motion skills to shoot a 52 second (232 frame) movie. |
|
So You Think You Can Scale Up Autonomous Robot Data Collection? Suvir Mirchandani, Suneel Belkhale, Joey Hejna, Evelyn Choi, Md Sazzad Islam, Dorsa Sadigh Conference on Robot Learning (CoRL), November 2024
BibTeX
Abstract
arXiv
Website
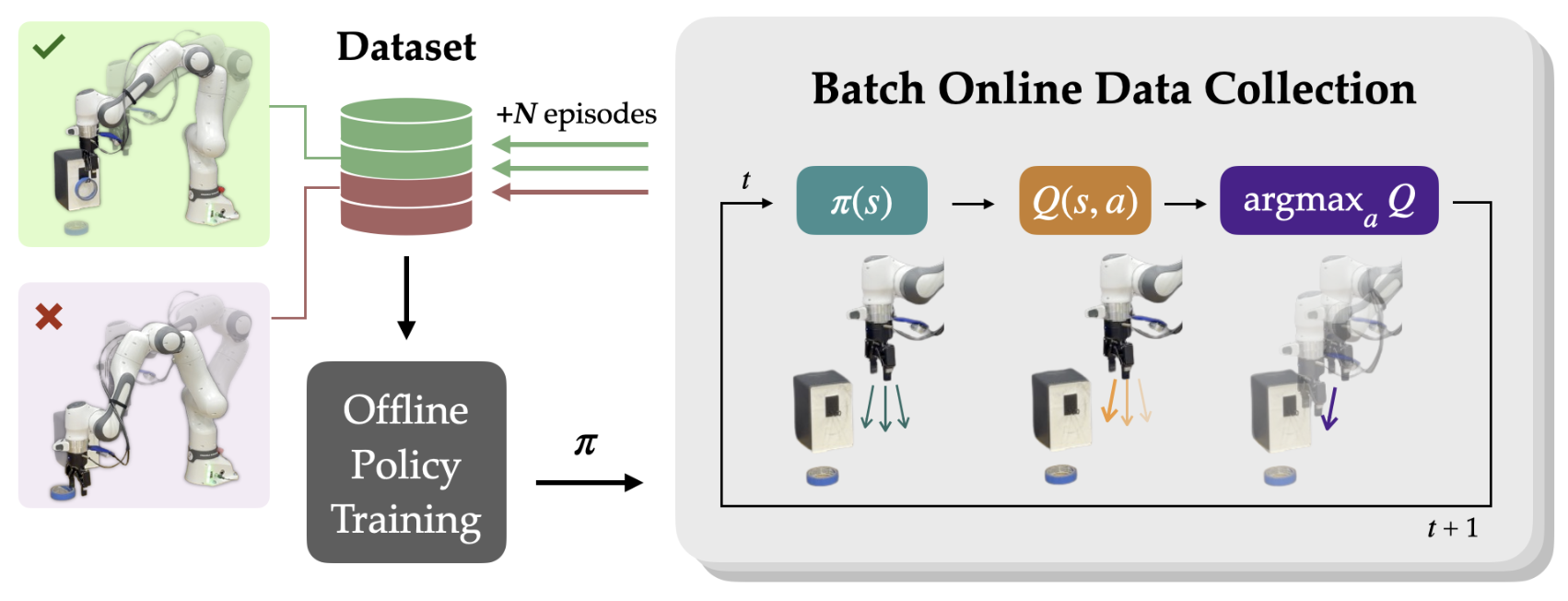
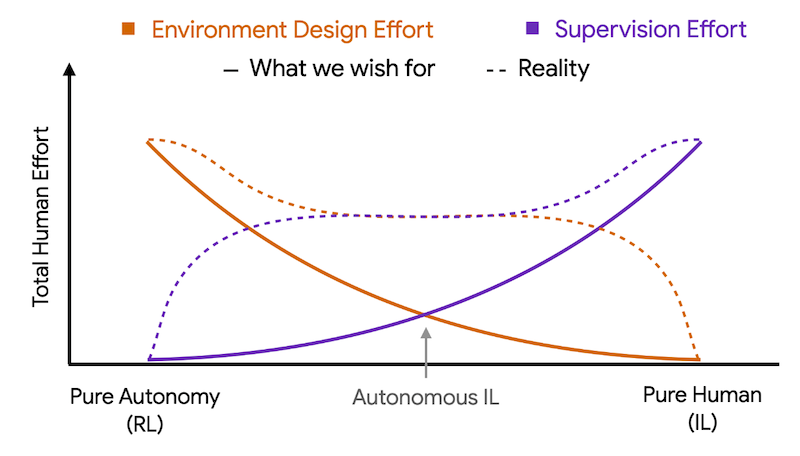
@inproceedings{mirchandani2024so, title={So You Think You Can Scale Up Autonomous Robot Data Collection?}, author={Mirchandani, Suvir and Belkhale, Suneel and Hejna, Joey and Choi, Evelyn and Islam, Md Sazzad and Sadigh, Dorsa}, booktitle={Conference on Robot Learning (CoRL)}, year={2024}, month=nov } A long-standing goal in robot learning is to develop methods for robots to acquire new skills autonomously. While reinforcement learning (RL) comes with the promise of enabling autonomous data collection, it remains challenging to scale in the real-world partly due to the significant effort required for environment design and instrumentation, including the need for designing reset functions or accurate success detectors. On the other hand, imitation learning (IL) methods require little to no environment design effort, but instead require significant human supervision in the form of collected demonstrations. To address these shortcomings, recent works in autonomous IL start with an initial seed dataset of human demonstrations that an autonomous policy can bootstrap from. While autonomous IL approaches come with the promise of addressing the challenges of autonomous RL as well as pure IL strategies, in this work, we posit that such techniques do not deliver on this promise and are still unable to scale up autonomous data collection in the real world. Through a series of real-world experiments, we demonstrate that these approaches, when scaled up to realistic settings, face much of the same scaling challenges as prior attempts in RL in terms of environment design. Further, we perform a rigorous study of autonomous IL methods across different data scales and 7 simulation and real-world tasks, and demonstrate that while autonomous data collection can modestly improve performance, simply collecting more human data often provides significantly more improvement. Our work suggests a negative result: that scaling up autonomous data collection for learning robot policies for real-world tasks is more challenging and impractical than what is suggested in prior work. We hope these insights about the core challenges of scaling up data collection help inform future efforts in autonomous learning. |
|
Imitation Bootstrapped Reinforcement Learning Hengyuan Hu, Suvir Mirchandani, Dorsa Sadigh Robotics: Science and Systems (RSS), July 2024
BibTeX
Abstract
arXiv
Website
Code
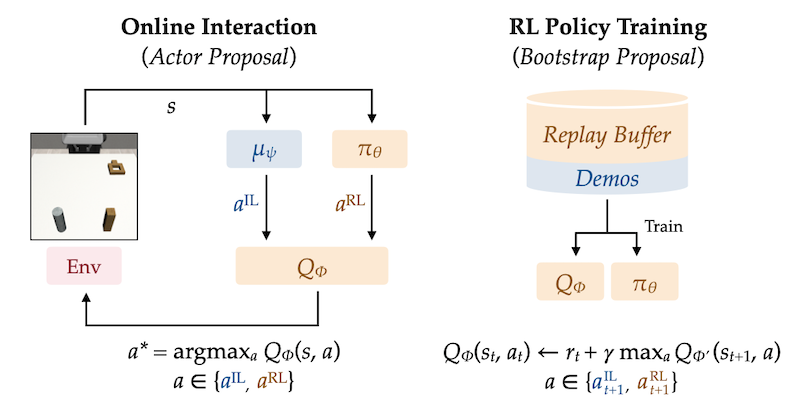
@inproceedings{hu2024imitation, title={Imitation Bootstrapped Reinforcement Learning}, author={Hu, Hengyuan and Mirchandani, Suvir and Sadigh, Dorsa}, booktitle={Robotics: Science and Systems (RSS)}, year={2024}, } Despite the considerable potential of reinforcement learning (RL), robotic control tasks predominantly rely on imitation learning (IL) due to its better sample efficiency. However, it is costly to collect comprehensive expert demonstrations that enable IL to generalize to all possible scenarios, and any distribution shift would require recollecting data for finetuning. Therefore, RL is appealing if it can build upon IL as an efficient autonomous self-improvement procedure. We propose imitation bootstrapped reinforcement learning (IBRL), a novel framework for sample-efficient RL with demonstrations that first trains an IL policy on the provided demonstrations and then uses it to propose alternative actions for both online exploration and bootstrapping target values. Compared to prior works that oversample the demonstrations or regularize RL with an additional imitation loss, IBRL is able to utilize high quality actions from IL policies since the beginning of training, which greatly accelerates exploration and training efficiency. We evaluate IBRL on 6 simulation and 3 real-world tasks spanning various difficulty levels. IBRL significantly outperforms prior methods and the improvement is particularly more prominent in harder tasks. |

|
DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset Alexander Khazatsky*, Karl Pertsch*, et al. Robotics: Science and Systems (RSS), July 2024
BibTeX
Abstract
arXiv
Website
@inproceedings{khazatsky2024droid, title = {DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset}, author = {Alexander Khazatsky and Karl Pertsch and Suraj Nair and Ashwin Balakrishna and Sudeep Dasari and Siddharth Karamcheti and Soroush Nasiriany and Mohan Kumar Srirama and Lawrence Yunliang Chen and Kirsty Ellis and Peter David Fagan and Joey Hejna and Masha Itkina and Marion Lepert and Yecheng Jason Ma and Patrick Tree Miller and Jimmy Wu and Suneel Belkhale and Shivin Dass and Huy Ha and Arhan Jain and Abraham Lee and Youngwoon Lee and Marius Memmel and Sungjae Park and Ilija Radosavovic and Kaiyuan Wang and Albert Zhan and Kevin Black and Cheng Chi and Kyle Beltran Hatch and Shan Lin and Jingpei Lu and Jean Mercat and Abdul Rehman and Pannag R Sanketi and Archit Sharma and Cody Simpson and Quan Vuong and Homer Rich Walke and Blake Wulfe and Ted Xiao and Jonathan Heewon Yang and Arefeh Yavary and Tony Z. Zhao and Christopher Agia and Rohan Baijal and Mateo Guaman Castro and Daphne Chen and Qiuyu Chen and Trinity Chung and Jaimyn Drake and Ethan Paul Foster and Jensen Gao and David Antonio Herrera and Minho Heo and Kyle Hsu and Jiaheng Hu and Donovon Jackson and Charlotte Le and Yunshuang Li and Kevin Lin and Roy Lin and Zehan Ma and Abhiram Maddukuri and Suvir Mirchandani and Daniel Morton and Tony Nguyen and Abigail O'Neill and Rosario Scalise and Derick Seale and Victor Son and Stephen Tian and Emi Tran and Andrew E. Wang and Yilin Wu and Annie Xie and Jingyun Yang and Patrick Yin and Yunchu Zhang and Osbert Bastani and Glen Berseth and Jeannette Bohg and Ken Goldberg and Abhinav Gupta and Abhishek Gupta and Dinesh Jayaraman and Joseph J Lim and Jitendra Malik and Roberto Martín-Martín and Subramanian Ramamoorthy and Dorsa Sadigh and Shuran Song and Jiajun Wu and Michael C. Yip and Yuke Zhu and Thomas Kollar and Sergey Levine and Chelsea Finn}, booktitle={Robotics: Science and Systems (RSS)}, year = {2024}, } The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350h of interaction data, collected across 564 scenes and 86 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance, greater robustness, and improved generalization ability. We open source the full dataset, code for policy training, and a detailed guide for reproducing our robot hardware setup. |

|
Open X-Embodiment: Robotic Learning Datasets and RT-X Models Open X-Embodiment Collaboration International Conference on Robotics and Automation (ICRA), May 2024 Best Conference Paper Award
BibTeX
arXiv
Website
@article{open_x_embodiment_rt_x_2023, title = {Open {X-E}mbodiment: Robotic Learning Datasets and {RT-X} Models}, author = {Open X-Embodiment Collaboration and Abby O'Neill and Abdul Rehman and Abhinav Gupta and Abhiram Maddukuri and Abhishek Gupta and Abhishek Padalkar and Abraham Lee and Acorn Pooley and Agrim Gupta and Ajay Mandlekar and Ajinkya Jain and Albert Tung and Alex Bewley and Alex Herzog and Alex Irpan and Alexander Khazatsky and Anant Rai and Anchit Gupta and Andrew Wang and Andrey Kolobov and Anikait Singh and Animesh Garg and Aniruddha Kembhavi and Annie Xie and Anthony Brohan and Antonin Raffin and Archit Sharma and Arefeh Yavary and Arhan Jain and Ashwin Balakrishna and Ayzaan Wahid and Ben Burgess-Limerick and Beomjoon Kim and Bernhard Schölkopf and Blake Wulfe and Brian Ichter and Cewu Lu and Charles Xu and Charlotte Le and Chelsea Finn and Chen Wang and Chenfeng Xu and Cheng Chi and Chenguang Huang and Christine Chan and Christopher Agia and Chuer Pan and Chuyuan Fu and Coline Devin and Danfei Xu and Daniel Morton and Danny Driess and Daphne Chen and Deepak Pathak and Dhruv Shah and Dieter Büchler and Dinesh Jayaraman and Dmitry Kalashnikov and Dorsa Sadigh and Edward Johns and Ethan Foster and Fangchen Liu and Federico Ceola and Fei Xia and Feiyu Zhao and Felipe Vieira Frujeri and Freek Stulp and Gaoyue Zhou and Gaurav S. Sukhatme and Gautam Salhotra and Ge Yan and Gilbert Feng and Giulio Schiavi and Glen Berseth and Gregory Kahn and Guangwen Yang and Guanzhi Wang and Hao Su and Hao-Shu Fang and Haochen Shi and Henghui Bao and Heni Ben Amor and Henrik I Christensen and Hiroki Furuta and Homanga Bharadhwaj and Homer Walke and Hongjie Fang and Huy Ha and Igor Mordatch and Ilija Radosavovic and Isabel Leal and Jacky Liang and Jad Abou-Chakra and Jaehyung Kim and Jaimyn Drake and Jan Peters and Jan Schneider and Jasmine Hsu and Jay Vakil and Jeannette Bohg and Jeffrey Bingham and Jeffrey Wu and Jensen Gao and Jiaheng Hu and Jiajun Wu and Jialin Wu and Jiankai Sun and Jianlan Luo and Jiayuan Gu and Jie Tan and Jihoon Oh and Jimmy Wu and Jingpei Lu and Jingyun Yang and Jitendra Malik and João Silvério and Joey Hejna and Jonathan Booher and Jonathan Tompson and Jonathan Yang and Jordi Salvador and Joseph J. Lim and Junhyek Han and Kaiyuan Wang and Kanishka Rao and Karl Pertsch and Karol Hausman and Keegan Go and Keerthana Gopalakrishnan and Ken Goldberg and Kendra Byrne and Kenneth Oslund and Kento Kawaharazuka and Kevin Black and Kevin Lin and Kevin Zhang and Kiana Ehsani and Kiran Lekkala and Kirsty Ellis and Krishan Rana and Krishnan Srinivasan and Kuan Fang and Kunal Pratap Singh and Kuo-Hao Zeng and Kyle Hatch and Kyle Hsu and Laurent Itti and Lawrence Yunliang Chen and Lerrel Pinto and Li Fei-Fei and Liam Tan and Linxi 'Jim' Fan and Lionel Ott and Lisa Lee and Luca Weihs and Magnum Chen and Marion Lepert and Marius Memmel and Masayoshi Tomizuka and Masha Itkina and Mateo Guaman Castro and Max Spero and Maximilian Du and Michael Ahn and Michael C. Yip and Mingtong Zhang and Mingyu Ding and Minho Heo and Mohan Kumar Srirama and Mohit Sharma and Moo Jin Kim and Naoaki Kanazawa and Nicklas Hansen and Nicolas Heess and Nikhil J Joshi and Niko Suenderhauf and Ning Liu and Norman Di Palo and Nur Muhammad Mahi Shafiullah and Oier Mees and Oliver Kroemer and Osbert Bastani and Pannag R Sanketi and Patrick 'Tree' Miller and Patrick Yin and Paul Wohlhart and Peng Xu and Peter David Fagan and Peter Mitrano and Pierre Sermanet and Pieter Abbeel and Priya Sundaresan and Qiuyu Chen and Quan Vuong and Rafael Rafailov and Ran Tian and Ria Doshi and Roberto Mart{'i}n-Mart{'i}n and Rohan Baijal and Rosario Scalise and Rose Hendrix and Roy Lin and Runjia Qian and Ruohan Zhang and Russell Mendonca and Rutav Shah and Ryan Hoque and Ryan Julian and Samuel Bustamante and Sean Kirmani and Sergey Levine and Shan Lin and Sherry Moore and Shikhar Bahl and Shivin Dass and Shubham Sonawani and Shubham Tulsiani and Shuran Song and Sichun Xu and Siddhant Haldar and Siddharth Karamcheti and Simeon Adebola and Simon Guist and Soroush Nasiriany and Stefan Schaal and Stefan Welker and Stephen Tian and Subramanian Ramamoorthy and Sudeep Dasari and Suneel Belkhale and Sungjae Park and Suraj Nair and Suvir Mirchandani and Takayuki Osa and Tanmay Gupta and Tatsuya Harada and Tatsuya Matsushima and Ted Xiao and Thomas Kollar and Tianhe Yu and Tianli Ding and Todor Davchev and Tony Z. Zhao and Travis Armstrong and Trevor Darrell and Trinity Chung and Vidhi Jain and Vikash Kumar and Vincent Vanhoucke and Wei Zhan and Wenxuan Zhou and Wolfram Burgard and Xi Chen and Xiangyu Chen and Xiaolong Wang and Xinghao Zhu and Xinyang Geng and Xiyuan Liu and Xu Liangwei and Xuanlin Li and Yansong Pang and Yao Lu and Yecheng Jason Ma and Yejin Kim and Yevgen Chebotar and Yifan Zhou and Yifeng Zhu and Yilin Wu and Ying Xu and Yixuan Wang and Yonatan Bisk and Yongqiang Dou and Yoonyoung Cho and Youngwoon Lee and Yuchen Cui and Yue Cao and Yueh-Hua Wu and Yujin Tang and Yuke Zhu and Yunchu Zhang and Yunfan Jiang and Yunshuang Li and Yunzhu Li and Yusuke Iwasawa and Yutaka Matsuo and Zehan Ma and Zhuo Xu and Zichen Jeff Cui and Zichen Zhang and Zipeng Fu and Zipeng Lin}, journal = {arXiv}, year = {2023}, } |

|
RoboVQA: Multimodal Long-Horizon Reasoning for Robotics Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, Pete Florence, Wei Han, Robert Baruch, Yao Lu, Suvir Mirchandani, Peng Xu, Pannag Sanketi, Karol Hausman, Izhak Shafran, Brian Ichter, Yuan Cao International Conference on Robotics and Automation (ICRA), May 2024
BibTeX
Abstract
arXiv
Website
Code
@inproceedings{sermanet2024robovqa, title={RoboVQA: Multimodal Long-Horizon Reasoning for Robotics}, author={Pierre Sermanet and Tianli Ding and Jeffrey Zhao and Fei Xia and Debidatta Dwibedi and Keerthana Gopalakrishnan and Christine Chan and Gabriel Dulac-Arnold and Sharath Maddineni and Nikhil J Joshi and Pete Florence and Wei Han and Robert Baruch and Yao Lu and Suvir Mirchandani and Peng Xu and Pannag Sanketi and Karol Hausman and Izhak Shafran and Brian Ichter and Yuan Cao}, booktitle={Proceedings of International Conference in Robotics and Automation (ICRA)}, year={2024} } We present a scalable, bottom-up and intrinsically diverse data collection scheme that can be used for high-level reasoning with long and medium horizons and that has 2.2x higher throughput compared to traditional narrow top-down step-by-step collection. We collect realistic data by performing any user requests within the entirety of 3 office buildings and using multiple robot and human embodiments. With this data, we show that models trained on all embodiments perform better than ones trained on the robot data only, even when evaluated solely on robot episodes. We find that for a fixed collection budget it is beneficial to take advantage of cheaper human collection along with robot collection. We release a large and highly diverse (29,520 unique instructions) dataset dubbed RoboVQA containing 829,502 (video, text) pairs for robotics-focused visual question answering. We also demonstrate how evaluating real robot experiments with an intervention mechanism enables performing tasks to completion, making it deployable with human oversight even if imperfect while also providing a single performance metric. We demonstrate a single video-conditioned model named RoboVQA-VideoCoCa trained on our dataset that is capable of performing a variety of grounded high-level reasoning tasks in broad realistic settings with a cognitive intervention rate 46% lower than the zero-shot state of the art visual language model (VLM) baseline and is able to guide real robots through long-horizon tasks. The performance gap with zero-shot state-of-the-art models indicates that a lot of grounded data remains to be collected for real-world deployment, emphasizing the critical need for scalable data collection approaches. Finally, we show that video VLMs significantly outperform single-image VLMs with an average error rate reduction of 19% across all VQA tasks. Data and videos available at robovqa.github.io |
|
Large Language Models as General Pattern Machines Suvir Mirchandani, Fei Xia, Pete Florence, Brian Ichter, Danny Driess, Montserrat Gonzalez Arenas, Kanishka Rao, Dorsa Sadigh, Andy Zeng Conference on Robot Learning (CoRL), November 2023
BibTeX
Abstract
arXiv
Website
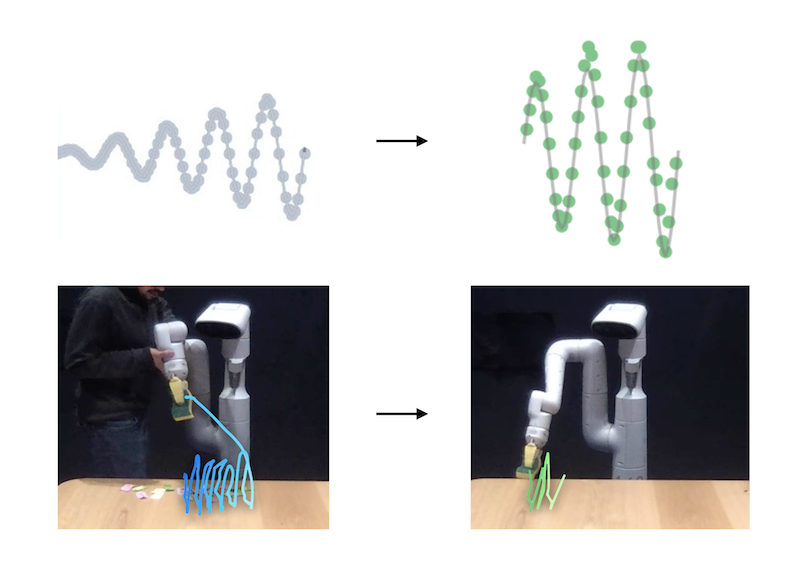
@inproceedings{mirchandani2023large, title={Large Language Models as General Pattern Machines}, author={Mirchandani, Suvir and Xia, Fei and Florence, Pete and Ichter, Brian and Driess, Danny and Arenas, Montserrat Gonzalez and Rao, Kanishka and Sadigh, Dorsa and Zeng, Andy}, booktitle={Conference on Robot Learning (CoRL)}, year={2023}, } We observe that pre-trained large language models (LLMs) are capable of autoregressively completing complex token sequences -- from arbitrary ones procedurally generated by probabilistic context-free grammars (PCFG), to more rich spatial patterns found in the Abstract Reasoning Corpus (ARC), a general AI benchmark, prompted in the style of ASCII art. Surprisingly, pattern completion proficiency can be partially retained even when the sequences are expressed using tokens randomly sampled from the vocabulary. These results suggest that without any additional training, LLMs can serve as general sequence modelers, driven by in-context learning. In this work, we investigate how these zero-shot capabilities may be applied to problems in robotics -- from extrapolating sequences of numbers that represent states over time to complete simple motions, to least-to-most prompting of reward-conditioned trajectories that can discover and represent closed-loop policies (e.g., a stabilizing controller for CartPole). While difficult to deploy today for real systems due to latency, context size limitations, and compute costs, the approach of using LLMs to drive low-level control may provide an exciting glimpse into how the patterns among words could be transferred to actions. |
|
Assistive Teaching of Motor Control Tasks to Humans Megha Srivastava, Erdem Bıyık, Suvir Mirchandani, Noah Goodman, Dorsa Sadigh Conference on Neural Information Processing Systems (NeurIPS), November 2022
BibTeX
Abstract
arXiv
Code
Talk
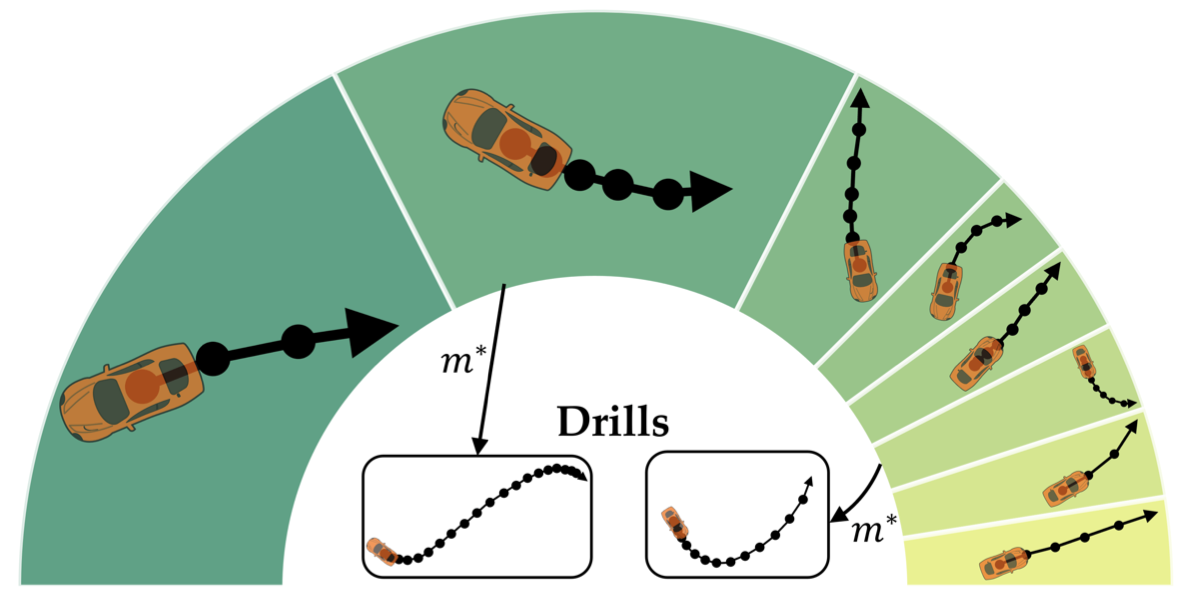
@inproceedings{srivastava2022assistive, title={Assistive Teaching of Motor Control Tasks to Humans}, author={Srivastava, Megha and Biyik, Erdem and Mirchandani, Suvir and Goodman, Noah and Sadigh, Dorsa}, booktitle={Conference on Neural Information Processing Systems (NeurIPS)}, year={2022}, } Recent works on shared autonomy and assistive-AI technologies, such as assistive robot teleoperation, seek to model and help human users with limited ability in a fixed task. However, these approaches often fail to account for humans' ability to adapt and eventually learn how to execute a control task themselves. Furthermore, in applications where it may be desirable for a human to intervene, these methods may inhibit their ability to learn how to succeed with full self-control. In this paper, we focus on the problem of assistive teaching of motor control tasks such as parking a car or landing an aircraft. Despite their ubiquitous role in humans' daily activities and occupations, motor tasks are rarely taught in a uniform way due to their high complexity and variance. We propose an AI-assisted teaching algorithm that leverages skill discovery methods from reinforcement learning (RL) to (i) break down any motor control task into teachable skills, (ii) construct novel drill sequences, and (iii) individualize curricula to students with different capabilities. Through an extensive mix of synthetic and user studies on two motor control tasks -- parking a car with a joystick and writing characters from the Balinese alphabet -- we show that assisted teaching with skills improves student performance by around 40% compared to practicing full trajectories without skills, and practicing with individualized drills can result in up to 25% further improvement. Our source code is available at https://github.com/Stanford-ILIAD/teaching. |
|
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning Suvir Mirchandani, Licheng Yu, Mengjiao Wang, Animesh Sinha, Wenwen Jiang, Tao Xiang, Ning Zhang Conference on Empirical Methods in Natural Language Processing (EMNLP), December 2022
BibTeX
Abstract
arXiv
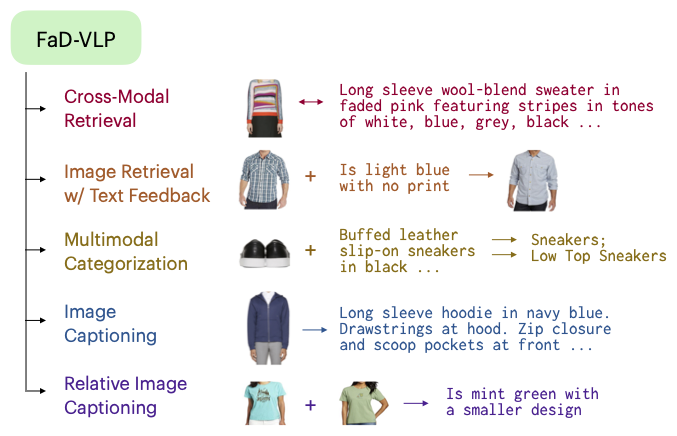
@inproceedings{mirchandani2022fadvlp, title={FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning}, author={Mirchandani, Suvir and Yu, Licheng and Wang, Mengjiao and Sinha, Animesh and Jiang, Wenwen and Xiang, Tao and Zhang, Ning}, booktitle={Conference on Empirical Methods in Natural Language Processing (EMNLP)}, year={2022}, } Multimodal tasks in the fashion domain have significant potential for e-commerce, but involve challenging vision-and-language learning problems - e.g., retrieving a fashion item given a reference image plus text feedback from a user. Prior works on multimodal fashion tasks have either been limited by the data in individual benchmarks, or have leveraged generic vision-and-language pre-training but have not taken advantage of the characteristics of fashion data. Additionally, these works have mainly been restricted to multimodal understanding tasks. To address these gaps, we make two key contributions. First, we propose a novel fashion-specific pre-training framework based on weakly-supervised triplets constructed from fashion image-text pairs. We show the triplet-based tasks are an effective addition to standard multimodal pre-training tasks. Second, we propose a flexible decoder-based model architecture capable of both fashion retrieval and captioning tasks. Together, our model design and pre-training approach are competitive on a diverse set of fashion tasks, including cross-modal retrieval, image retrieval with text feedback, image captioning, relative image captioning, and multimodal categorization. |
|
How do People Incorporate Advice from Artificial Agents when Making Physical Judgments? Erik Brockbank*, Haoliang Wang*, Justin Yang, Suvir Mirchandani, Erdem Bıyık, Dorsa Sadigh, Judith Fan Cognitive Science Society Conference (CogSci), July 2022 Oral Presentation
BibTeX
Abstract
arXiv
Code
Talk
@inproceedings{brockbank2022people, title={How do People Incorporate Advice from Artificial Agents when Making Physical Judgments?}, author={Brockbank, Erik and Wang, Haoliang and Yang, Justin and Mirchandani, Suvir and Biyik, Erdem and Sadigh, Dorsa and Fan, Judith}, booktitle={Annual Meeting of the Cognitive Science Society (CogSci)}, year={2022}, month=jul } How do people build up trust with artificial agents? Here, we study a key component of interpersonal trust: people’s ability to evaluate the competence of another agent across repeated interactions. Prior work has largely focused on appraisal of simple, static skills; in contrast, we probe competence evaluations in a rich setting with agents that learn over time. Participants played a video game involving physical reasoning paired with one of four artificial agents that suggested moves each round. We measure participants’ decisions to accept or revise their partner’s suggestions to understand how people evaluated their partner’s ability. Overall, participants collaborated successfully with their agent partners; however, when revising their partner’s suggestions, people made sophisticated inferences about the competence of their partner from prior behavior. Results provide a quantitative measure of how people integrate a partner’s competence into their own decisions and may help facilitate better coordination between humans and artificial agents. |
|
ELLA: Exploration through Learned Language Abstraction Suvir Mirchandani, Siddharth Karamcheti, Dorsa Sadigh Conference on Neural Information Processing Systems (NeurIPS), December 2021
BibTeX
Abstract
arXiv
Code
Talk
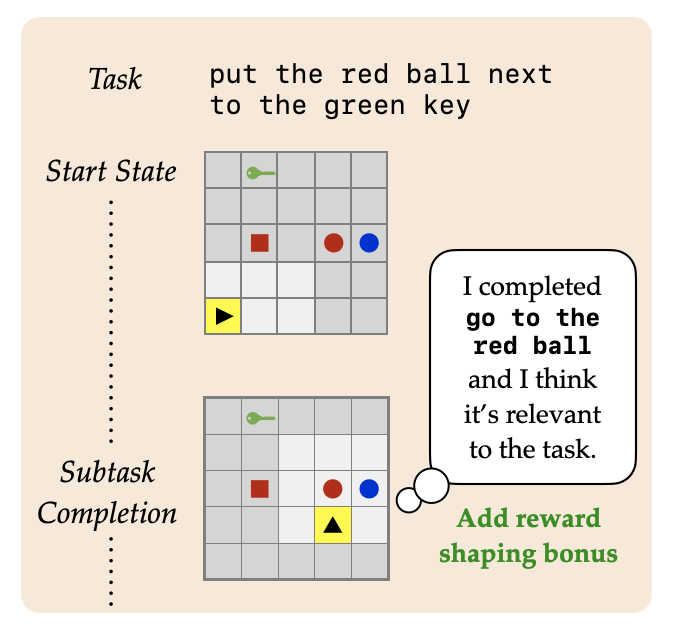
@inproceedings{mirchandani2021ella, title={ELLA: Exploration through Learned Language Abstraction}, author={Mirchandani, Suvir and Karamcheti, Siddharth and Sadigh, Dorsa}, booktitle={Conference on Neural Information Processing Systems (NeurIPS)}, year={2021}, } Building agents capable of understanding language instructions is critical to effective and robust human-AI collaboration. Recent work focuses on training these agents via reinforcement learning in environments with synthetic language; however, instructions often define long-horizon, sparse-reward tasks, and learning policies requires many episodes of experience. We introduce ELLA: Exploration through Learned Language Abstraction, a reward shaping approach geared towards boosting sample efficiency in sparse reward environments by correlating high-level instructions with simpler low-level constituents. ELLA has two key elements: 1) A termination classifier that identifies when agents complete low-level instructions, and 2) A relevance classifier that correlates low-level instructions with success on high-level tasks. We learn the termination classifier offline from pairs of instructions and terminal states. Notably, in departure from prior work in language and abstraction, we learn the relevance classifier online, without relying on an explicit decomposition of high-level instructions to low-level instructions. On a suite of complex BabyAI environments with varying instruction complexities and reward sparsity, ELLA shows gains in sample efficiency relative to language-based shaping and traditional RL methods. |
|
On the Opportunities and Risks of Foundation Models Rishi Bommasani et al.; Robotics (§2.3): Siddharth Karamcheti, Annie Chen, Suvir Mirchandani, Suraj Nair, Krishnan Srinivasan, Kyle Hsu, Jeannette Bohg, Dorsa Sadigh, Chelsea Finn Center for Research on Foundation Models (CRFM), August 2021
BibTeX
Abstract
arXiv
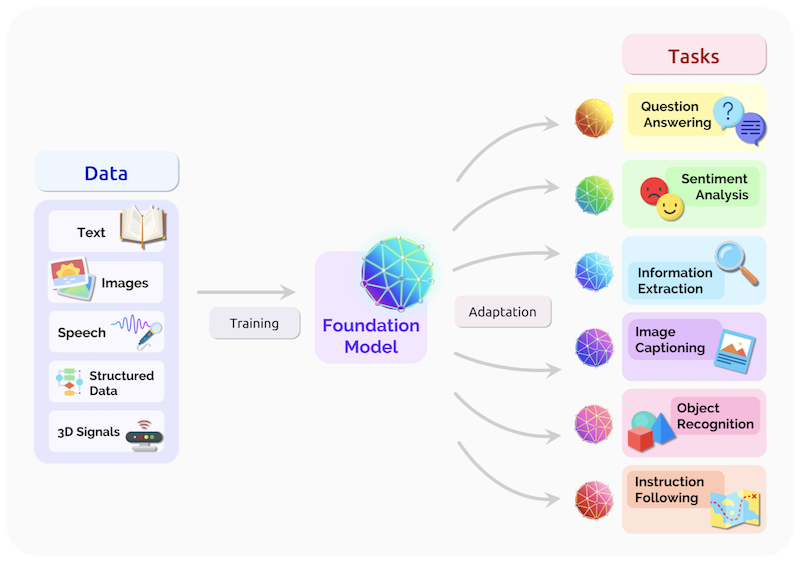
@article{bommasani2021foundation, title={On the Opportunities and Risks of Foundation Models}, author={Rishi Bommasani and Drew A. Hudson and Ehsan A deli and Russ Altman and Simran Arora and Sydney von Arx and Michael S. Bernstein and Jeannette Bohg and Antoine Bosselut and Emma Brunskill and Erik Brynjolfsson and S. Buch and Dallas Card and Rodrigo Castellon and Niladri S. Chatterji and Annie S. Chen and Kathleen A. Creel and Jared Davis and Dora Demszky and Chris Donahue and Moussa Doumbouya and Esin Durmus and Stefano Ermon and John Etchemendy and Kawin Ethayarajh and Li Fei-Fei and Chelsea Finn and Trevor Gale and Lauren E. Gillespie and Karan Goel and Noah D. Goodman and Shelby Grossman and Neel Guha and Tatsunori Hashimoto and Peter Henderson and John Hewitt and Daniel E. Ho and Jenny Hong and Kyle Hsu and Jing Huang and Thomas F. Icard and Saahil Jain and Dan Jurafsky and Pratyusha Kalluri and Siddharth Karamcheti and Geoff Keeling and Fereshte Khani and O. Khattab and Pang Wei Koh and Mark S. Krass and Ranjay Krishna and Rohith Kuditipudi and Ananya Kumar and Faisal Ladhak and Mina Lee and Tony Lee and Jure Leskovec and Isabelle Levent and Xiang Lisa Li and Xuechen Li and Tengyu Ma and Ali Malik and Christopher D. Manning and Suvir P. Mirchandani and Eric Mitchell and Zanele Munyikwa and Suraj Nair and Avanika Narayan and Deepak Narayanan and Benjamin Newman and Allen Nie and Juan Carlos Niebles and Hamed Nilforoshan and J. F. Nyarko and Giray Ogut and Laurel Orr and Isabel Papadimitriou and Joon Sung Park and Chris Piech and Eva Portelance and Christopher Potts and Aditi Raghunathan and Robert Reich and Hongyu Ren and Frieda Rong and Yusuf H. Roohani and Camilo Ruiz and Jack Ryan and Christopher Re and Dorsa Sadigh and Shiori Sagawa and Keshav Santhanam and Andy Shih and Krishna Parasuram Srinivasan and Alex Tamkin and Rohan Taori and Armin W. Thomas and Florian Tram{\`e}r and Rose E. Wang and William Wang and Bohan Wu and Jiajun Wu and Yuhuai Wu and Sang Michael Xie and Michihiro Yasunaga and Jiaxuan You and Matei A. Zaharia and Michael Zhang and Tianyi Zhang and Xikun Zhang and Yuhui Zhang and Lucia Zheng and Kaitlyn Zhou and Percy Liang}, journal={ArXiv}, year={2021}, url={https://crfm.stanford.edu/assets/report.pdf} } AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature. |
© 2026 Suvir Mirchandani